
Tyler Griggs$^{1}$$^{\dagger}$, Sumanth Hegde$^{2}$, Eric Tang$^{2}$, Shu Liu$^{1}$, Shiyi Cao$^{1}$, Dacheng Li$^{1}$, Charlie Ruan$^{1}$*, Philipp Moritz$^{2}$, Kourosh Hakhamaneshi$^{2}$, Richard Liaw$^{2}$, Akshay Malik$^{2}$, **** Shishir G. Patil$^{1}$ Matei Zaharia$^{1}$, Joseph E. Gonzalez$^{1}$, Ion Stoica$^{1}$
$^{1}$University of California, Berkeley
$^{2}$Anyscale
$^{\dagger}$Project Lead
*Core Contributor
🗓️ Posted: June 26, 2025
<aside> 🏋️
In the original release of SkyRL, we introduced an agentic layer in the RL stack for multi-turn tool use LLMs, optimized for long-horizon, real-environment tasks like SWE-Bench.
Today, we are upgrading SkyRL to a highly-modular RL framework to train LLMs with the introduction of two key additions:
A modular, performant RL framework for training LLMs. SkyRL makes it easy to prototype new training algorithms, environments, and training execution plans — without compromising usability or speed.
A gymnasium of tool-use tasks with a simple environment interface and an ****out-of-the box library of popular tasks ****such as math, code, search, and SQL.
SkyRL’s modularity enables easy implementation of real-world improvements—like async training, heterogeneous hardware, and new environments — with under 100 LoC and up to 1.8× faster training.
Try it out at SkyRL on GitHub:
From the NovaSkyAI team at UC Berkeley Sky Computing Lab.
</aside>
Post-training is unlocking new capabilities in the development of LLMs. Reinforcement learning (RL) is arguably the most complex post-training workload as it includes producing a large volume of model responses (inference engines), executing actions generated by the model responses for a task (environments), and updating model parameters based on these actions’ rewards (trainers). The requirements for each of these components are diverse and, as the community rapidly explores and develops new RL techniques, the requirements continue to evolve.
We found that many existing RL frameworks tightly couple core components and lack clear interfaces for implementing custom logic. As a result, prototyping new ideas is often cumbersome—changing one part of the stack typically requires modifying several others. This rigidity makes it hard for developers to adapt to the evolving requirements of RL and to freely explore innovations across the stack, whether in algorithms, execution plans, or environments.
Based on this insight, modularity emerged as our top concern. We built SkyRL-v0.1 to be highly modular and facilitate flexible modification and extension of each layer of the RL framework.
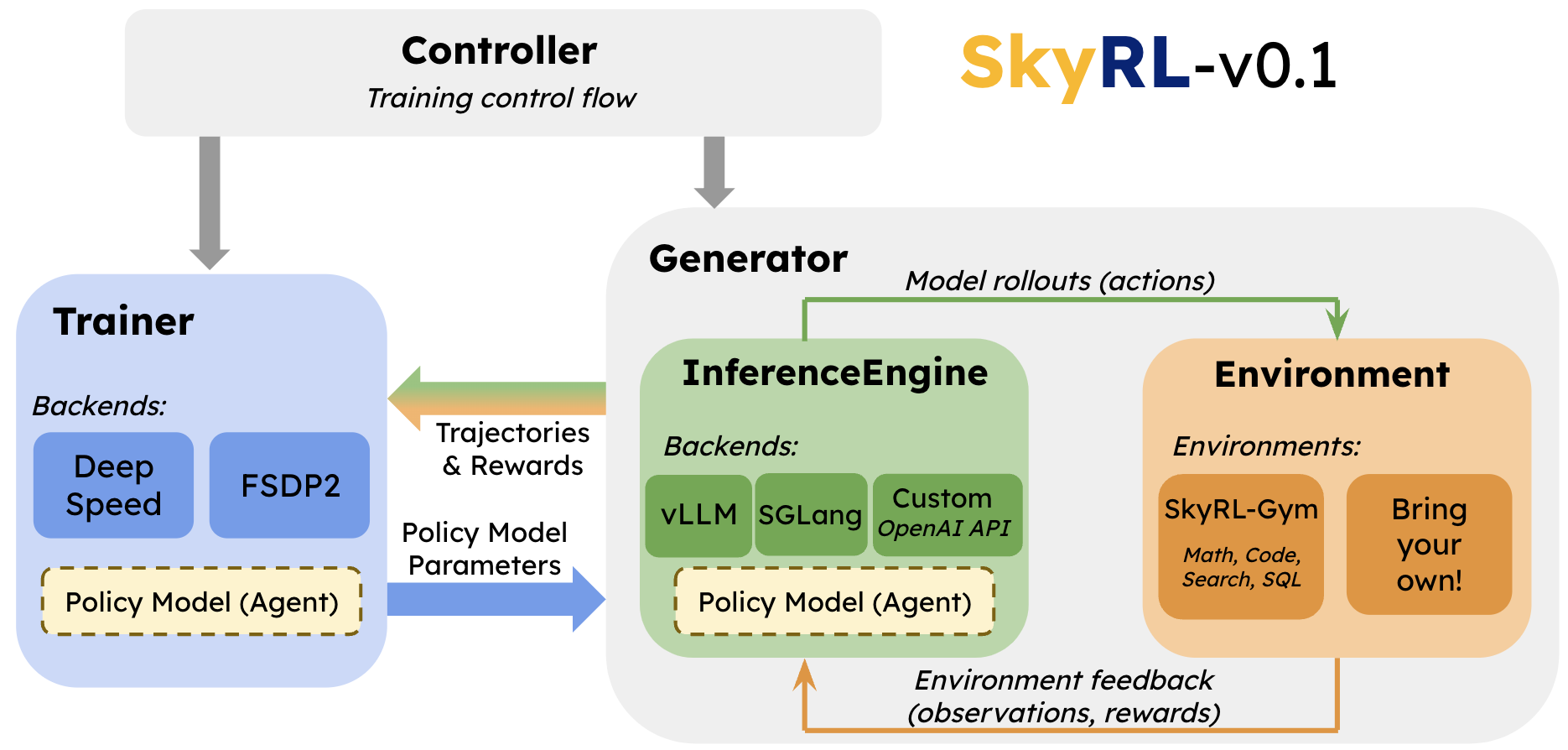
Figure 1. High-level architecture of SkyRL-v0.1’s core components.
SkyRL-v0.1 breaks the RL stack into modular components and provides well-defined public APIs for each of them. Specifically, as shown in Figure 1 above, we separate training into two major components, Trainer and Generator, and the Generator is further divided into InferenceEngine and Environment, with a single Controller managing setup and execution of each component. The components’ responsibilities are as follows: